今回のブログでは、研究をその目的によって以下のようなカテゴリーに分けることで、その研究で「何が言いたいのか?」ということを理解する方法をご説明したいと思います。ちなみにこれはいわゆる大学や研究機関でやっている研究だけでなく、ビジネスで行われるビッグ・データの解析でも、政府が行う調査や統計の解釈においても考え方は同じです。全てのデータ解析は、以下のどれかに当てはまるはずですし、逆に当てはまらないものは解析結果の解釈が難しくなるだけではなく、間違ってデータを読んでしまうリスクもあります。
研究の目的
- 因果関係および相関関係の検証(Causation & association)
- 予測モデル(Prediction model)
- 記述統計(Descriptive statistics)
1.因果関係および相関関係の検証(Causation & association)
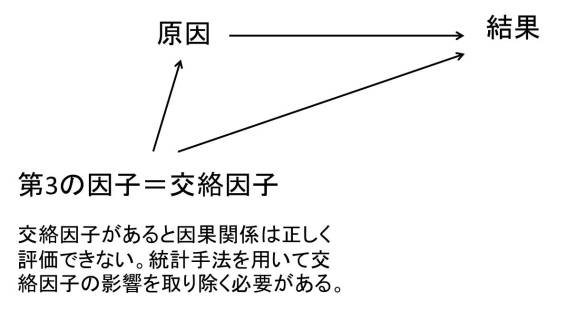
まず全体像から見ると、「因果推論」(Causal inference)(因果関係を明らかにする研究のことを因果推論と呼びます)が最も中心にあり、多くの科学的研究はこれを明らかにするために行われると言っても過言ではないと思います。もちろん医療経済学研究も、医療政策研究も、疫学研究も、興味関心の中心は因果推論になります。因果推論とは、2つの事象が「原因」とその「結果」であると言うことができるかどいうかを検証する研究です。言い換えると、原因が結果を引き起こしているのか明らかにする研究です。つまり「降圧薬を飲んだら、脳梗塞になる可能性が下がったか?」とか、「医療費の自己負担割合を上げたら、国民の健康状態が悪化したか?」などの疑問(Research question)を検証するのが因果推論です。これに対して、相関関係とは、原因と結果とは言えないものの、2つの事象のうちの1つが変化するのに合わせてもう片方も変化しているように見える関係が成り立つことを指します。後述する「交絡因子」が存在するためそのように見える場合などが考えられます※。交絡因子(Confounder)とは、原因と結果の両方に影響を与えるもののことです。つまり「第3の因子⇒原因」かつ「第3の因子⇒結果」が成り立つ場合に、この第3の因子のことを交絡因子と呼びます。交絡因子がなぜ問題なのかと言うと、XとYの間に交絡因子が存在している場合には、実際にはXとYの間に関係がなかったとしても、見かけ上、関係があるように見えてしまうからです。この場合、交絡因子を適切に補正(Adjustment)もしくは層別化(Stratification)することで、XとYの真の関係を調べることが可能になります。
※相関関係と訳される英語にはCorrelationとAssociationの2つあります。Correlationは2つの変数の間に線形の関係が成り立つことを言います。一方で、Associationは線形、非線形に関わらず2つの変数の間に関係があることを指します。Associationの中には因果関係が成り立つものもあれば、成り立たないものもあります。そして因果関係が成り立たない理由には、交絡因子や、原因となる変数が結果を引き起こしているのではなくその逆のパターン(疫学では逆の因果関係[Reverse causality]、経済学では同時性[Simultaneity]と呼ぶ)などがある。
例を用いてご説明します。あるデータを見てみると、健康診断を受けている人と受けていない人を比較すると、健康診断を受けている人達の方が糖尿病になっている割合が低かったとします。この結果を見て、健康診断は糖尿病の予防に役立っている、と解釈するのは正しいのでしょうか?健康診断を受けている人は(受けていない人と比べて)、一般的に健康への意識が高いので、食事も気を付けているでしょうし、運動もしている可能性が高いと考えられます。そうすると糖尿病にかかるリスクも必然的に下がります。
ここでは、そもそも違う(比較可能ではない=non-comparable)2群を比べていることが問題になります。この場合、「健康への意識」が交絡因子になりえます。健康への意識は、健康診断を受けるかどうかの決め手なりますし(健康への意識⇒健診受診)、糖尿病にかかるかどうかの原因にもなります(健康への意識⇒糖尿病の発症)。よって、例え健診受診(X)と糖尿病発症(Y)の間に何の関係もなかったとしても、健康への意識が交絡因子として作用することで、見かけ上は健診受診した方が糖尿病発症のリスクが下がるように見えてしまうのです。
この結果をもって健診に国が補助金を出すと、税金の無駄遣いになってしまいます。そのお金を例えば教育や他の公共サービスに使うことで、多くの日本人がより健康で幸福な暮らしを送ることができるようになるかもしれません。因果関係・相関関係を導く研究では、全ての因子(研究においてこのような因子のことを”変数(Variable)”と呼びます)を以下の3つのグループに分けることができます。解析する前にそれぞれがどの変数なのかをしっかりと見極めることが重要です。
- 原因(Cause)・・・経済学・医学では治療(Treatment)、疫学では暴露(Exposure)、心理学などでは独立変数(Independent variable)とも呼ばれる。介入と呼ばれることもある。
- 結果(Result)・・・アウトカム(Outcome)、心理学などでは従属変数(Dependent variable)とも呼ばれる
- 交絡因子(Confounder)・・・原因と結果の両方に影響を与える第3の変数のこと。経済学では欠落変数(Omitted variable)と呼ばれ、きちんと考慮しないと欠落変数バイアス(Omitted variable bias; OBV)を引き起こす。
ちなみに、交絡因子という言葉は疫学や医学研究で用いられます。経済学では、欠落変数と言い、これをきちんと考慮しないことで誤った(バイアスのかかった)因果関係を導き出してしまうことを、欠落変数バイアス(Omitted variable bias; OBV)と呼びますが、概念としては近いものになります。そして経済学では因果関係を導くことに強い関心を持っており、経済学は因果関係を導き出す学問であると言っても過言ではありません。
2.予測モデル(Prediction model)
医学研究などの中には予測モデルを組み立てることを主目的とした研究もあります。例えば、肺炎の患者さんが救急外来に来た時に、その患者さんの入院が必要になる確率を計算する予測式があります。これのことを予測モデルと呼びます。地震や津波のリスクを予測する統計手法も予測モデルになります。予測モデルに関しては、原因と結果であることを示す必要もなければ、交絡因子が存在していても問題はなく、あくまでどれだけ高い精度で予測できるかが至上命題になります。
肺炎患者さんの中で、女性の方が入院になる確率が高いとします。そうすると性別は予測モデルに含めるべき変数になります。一方で、女性は重症肺炎の「原因」ではありません。男性に性転換手術を受けてもらって女性になったところで肺炎が重症化するリスクが上がるわけでもなく、ホルモンなども含めて完璧に女性化させることに成功しても肺炎が悪化しやすくなるわけではありません。よって因果推論で性別を原因とすることにはそもそも無理があるのですが(注:因果推論では一般的に、性別のように実験などで操作できないものは原因としては認めないとされています)、予測モデルでは全く問題なく、予後予測に有用なのであればむしろ積極的に含めるべき変数になります。
研究を始めたばかりの方にしばしば見られるのが、手元にある変数を全て調べてみて、「どれか統計学的に有意になるものがないかな~?」と探索的に見てみるパターンです。これは因果推論・相関関係の研究でないことは、変数を、①原因、②結果、③交絡因子の3つに明確に区別できていないことより分かります。このような研究は予測モデルに近いものであると理解することもできるのですが(実際の予測モデルの作成プロセスはもっと洗練されたものですが・・・)、その解析結果をあたかも因果推論のように論じている研究もあり、これは実は問題です。
統計解析では、XとYの間に偶然関係があるように見えてしまう確率が1/20未満であるときに(慣習的に)「統計学的に有意な関係がある」と表現します。これはテストが1回しか行われなかった場合に用いられる概念ですので、やみくもに20個のテストを同時したら少なくとも一つは(実際には有意な関係がないにも関わらず)統計学的に有意な関係があるという結果になってしまいます。手元に20個の変数があったら、どれが原因でどれが交絡因子かを明らかにしないまま手当たりしだいに解析した場合には、少なくとも一つの変数はたままた統計学的に有意な結果が出てしまいます。これを英語では”Fishing”(魚釣り)と呼ばれ、やってはいけないご法度なのですが、それを防ぐためにも、データの解析を開始する前の段階で、(1)因果関係・相関関係が見たいのか、(2)予測モデルを組み立てたいのか、を明らかにしておく必要があると言うことができます。
3.記述統計(Descriptive statistics)
記述統計研究とは、事実をそのまま説明する研究です。西日本の方が東日本よりも人口当たりの医師数が多い、もしくは、心停止で倒れて病院に運ばれたときに歩いて(障害が残らずに)病院から出てこれる確率は住んでいる地域によって大きく異なる(論文)といった今の現状を説明する研究であるため、「説明する」という意味である”Descriptive”という表現が用いられています。西日本の方が東日本よりも人口当たりの医師数が多いことは分かりました、ではなぜそのような違いがあるのでしょうか?西日本の方が医学部の数が多いからではないでしょうか?と言うところまで突っ込んでいくと、「原因⇒結果」という関係に興味の中心が移っていくので、前述したような因果関係・相関関係を調べる研究になってきます。記述統計研究はあくまで今日本でどのようなことが起こっていて、どんなパターンがあるのかを、ざっくりと見る研究であり、因果関係・相関関係のようなことは言えません。
簡単にですが、(1)因果関係と相関関係、(2)予測モデル、(3)記述統計、という大きな枠組みで研究の目的を見てみました。まず重要なのは、より俯瞰的な視点から見た「この研究・解析で何が言いたいのか?」と言うことだと思います。これは研究だけでなく、データを読み解く時には常に必要な「統計リテラシー」でもあると考えます。
新聞記事を見ていたら、スマホを見ている時間が長い子供の方が成績が悪い、という記事がありました。往々にしてメディアや読者・視聴者は、スマホが成績低下を引き起こしているのではないか、と言う論調になりがちです。これには論理の飛躍があることが今回のブログを読んで頂くと分かると思います。スマホを見ている時間が長い子供の方が成績が悪いというのは、記述統計研究の結果です。事実をありのまま見ているだけですので、因果関係や相関関係のことをこの結果から論じることはできません。一方で、スマホが成績低下を引き起こす、という議論は因果関係を示唆していますが、このデータからは言うことができません。勉強が嫌いな子供ほどスマホを見ている時間が長いというのは十分考えられるメカニズムだと思います(「勉強が嫌い」であることが交絡因子であるということになります)。
ビッグ・データが注目を集めていますが、サンプルサイズがいくら大きくなっても交絡因子の問題は解消されないので注意が必要です。データが大きくなると推定の精度は上がるのですが(推定値の信頼区間が狭くなります)、バイアスを含んだままの間違った値をより高い精度で推定することになるので(高い精度を持って間違った値を推定してしまいます)、交絡因子によるバイアスの問題はむしろ大きくなってしまいます。これからのビッグ・データの時代、データや数字に騙されないためにも、このような基本的な考え方を身につけておく必要があると思われます。


面白く拝見させていただきました。
ビッグデータが流行りの昨今、「とりあえずデータを集めて分析すれば何か意味があることができる」という論調をたまに目にしますが、根本から間違っているわけですね。勉強になります。
いいねいいね: 1人
Uemura様、コメントありがとうございます。以前どこかの雑誌で「ビッグ・データがあれば因果関係のメカニズムを考えなくても良い」という趣旨の記事を読みましたが、これは誤解を招く表現だと思いました。ホームページ等で用いられる「A/Bテスト」(研究で言うところのランダム化比較試験)のことを指しているのであればこの議論はある程度正しいのですが、ほとんどのビッグ・データは他の目的のために収集された観察データ(Observational data)ですので、綿密な因果関係の検証を必要とします。統計学におけるバイアスの定義は「サンプルサイズがいくら大きくなっても小さくならない真実の値からのずれ」ですので、データが大きくなることが交絡因子・内生性などによるバイアスの問題を解消しないことが分かって頂けると思います(高い精度で間違った値を推定してしまうことになります)。データ・サイエンティストに一番重要なスキルセットは(プログラミングではなく)因果推論を正しく導くことのできる能力だと思います。今後ともよろしくお願いいたします。
いいねいいね