本日は「差分の差分分析」のご説明をします。疑似実験(Quasi-experiment)の研究デザインに関しては今回が最後になります。私の過去のブログを読んで頂ければ、疑似実験に関しては一通りカバーできるはずです。差分の差分分析は、英語ではDifference-in-differences designと呼ばれ、DID、DD、D-in-D、Diff-in-diffなどと略されます。このブログではDIDという略語を使わせて頂きます。
前後比較デザイン(Pre-post test design)
ある政策が導入され、その前後でアウトカムが測定されていた場合に、政策(介入)導入の前後のアウトカムの値を比較して、その差を政策の効果であると考えたくなります。例えば、ある病院で医療の質改善のプロジェクトを立ち上げることになったとします。プロジェクト導入前の院内感染の発生率が2%で、導入後の院内感染発生率は0.5%であったとします。この差である1.5%はこのプロジェクトの「介入効果」なのでしょうか?それとも、例えプロジェクトが導入されてなかったとしても、院内感染の発生率はいずれにしても0.5%まで下がっていたのでしょうか?
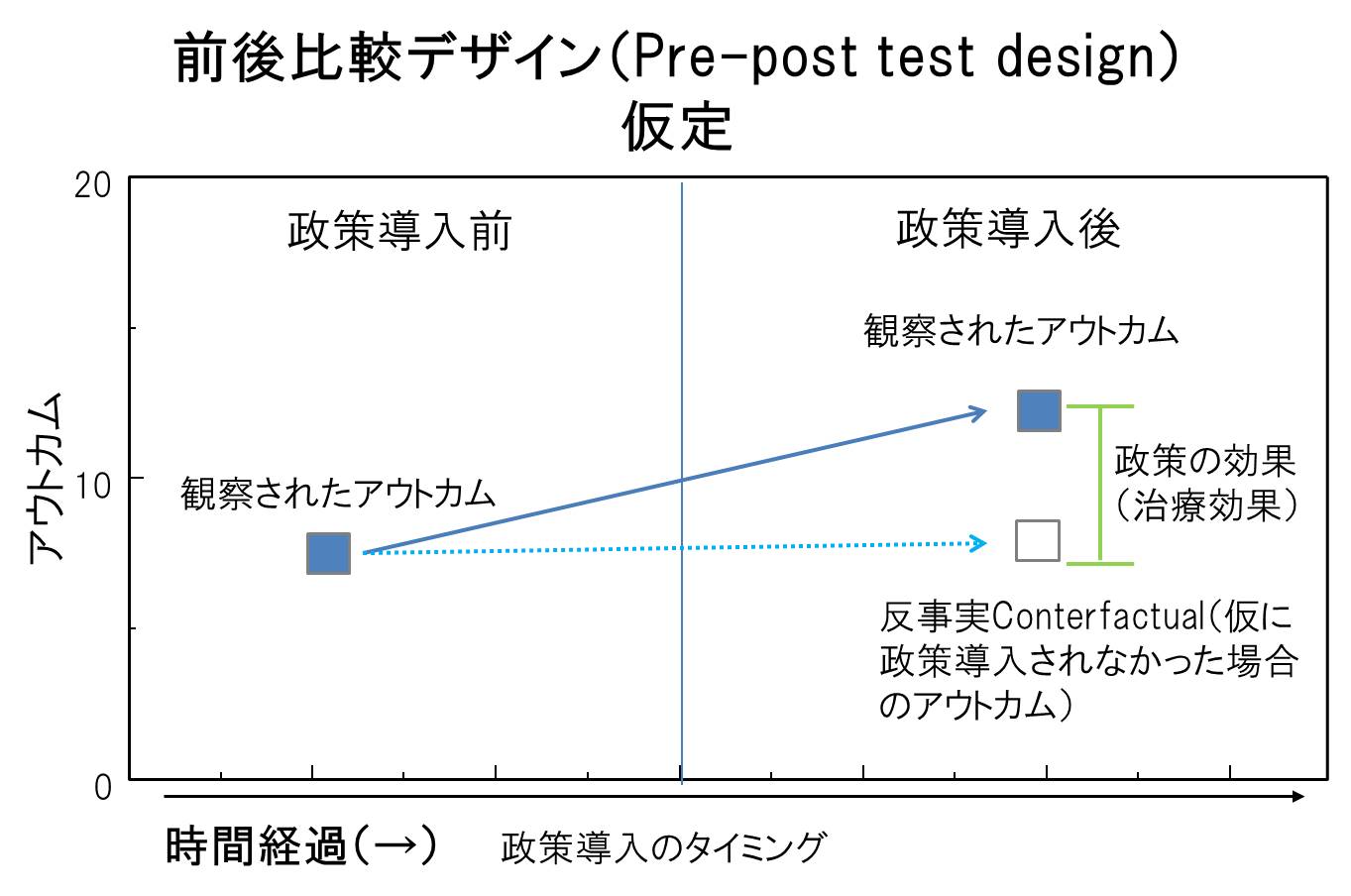
この様に、政策導入前のアウトカムとと導入後のアウトカムを単純に比較する研究デザインのことを「前後比較デザイン(Pre-post test design)」と呼びます。前後比較デザインでは、もし仮に政策が導入されなかった場合、アウトカムの値は全く変わらない(上がりも下がりもしない)という仮定が必要になります。図で示すと以下のように、もし仮に政策が導入されなければ、アウトカムは右の白い四角のように、政策導入前のアウトカムと同じレベルであるという仮定です。
しかし、実際には政策導入前から、アウトカムは改善し始めていることが多いと考えられます。下図で示すように、政策が導入されなかったシナリオでは、(アウトカムは変化しないわけではなく)白い四角の軌道のようなトレンドを描く場合が多いのです。その場合、本当は政策にはメリットが全くなかったとしても、解析結果は見かけ上、政策がなんらかの改善をもたらしているように見えてしまうことがあります(pre-post test designではバイアスの伴った介入効果を推定していまいます)。
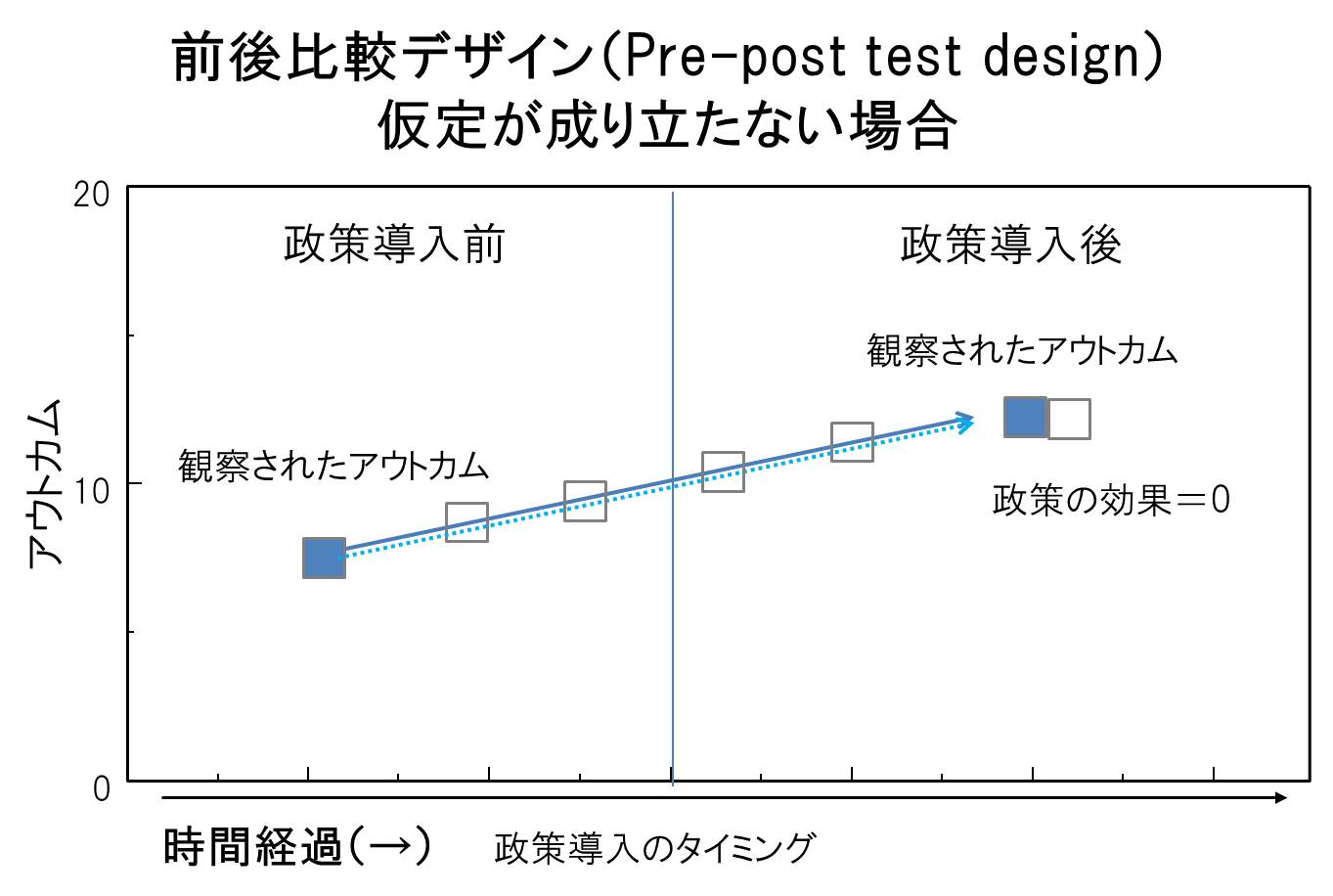
ちなみにこの前後比較デザインは疑似実験の中でも最も弱い(バイアスの無い推定をするのが難しい)デザインの一つであると考えられています。
差分の差分分析(Difference-in-differences design)
この前後比較デザインを改善したものがDIDになります。「前後比較デザイン」では自然経過のトレンドを考慮することができず、誤って政策の評価であるかのように見えてしまうことが問題です。この自然経過のトレンドの影響を取り除くことができるのがDIDです。DIDの歴史は1985年のAshenfelterとCardの論文までさかのぼります。DIDとは、介入群(政策の影響を受けたグループ)とコントロール群(政策の影響を受けなかったグループ)の2つのグループにおいて、政策導入前と導入後の2つのタイミングのデータを入手することから始まります。
DIDの名前が示す通り、2つの「差分(difference)」があります。1つ目の差分は政策導入の前後の比較です(前後比較デザインが推定している介入効果はこれになります)。そして2つ目の差分は介入群とコントロール群の比較です。
下のグラフをご覧ください。Y軸はアウトカムで、下に行くほど良いアウトカムであるとします。介入群のアウトカムにおいて、政策前後でA2-A1の変化があったとします。そしてコントロール群ではB2-B1の変化がありました。この場合、この2つの差である、(A2-A1)-(B2-B1)がDIDによって推定される政策のインパクトになります。このB2-B1を差し引くことで(政策が導入されなかった場合の)アウトカムの自然経過のトレンドを吸収することができます。このグラフは政策導入とアウトカムの間に相関が無い場合を示しています。この場合、 A2-A1)-(B2-B1)=0になります。
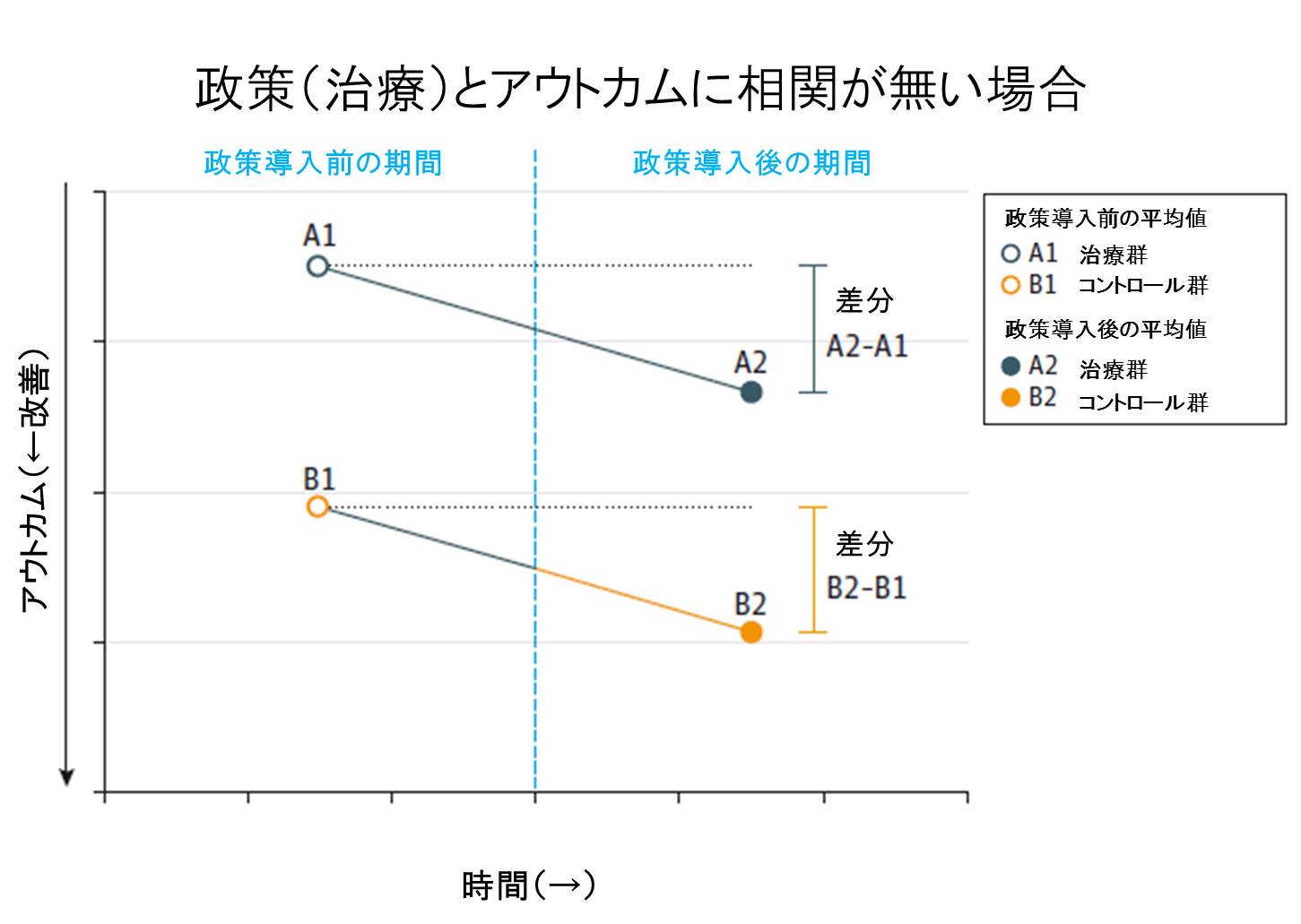
(出典:Dimick & Ryan, JAMA 2014を一部改変)
一方で、もし政策に効果がある場合には、アウトカムのトレンドは下図のようになり、(A2-A1)と(B2-B1)との差分が政策の効果(DIDの推定値)になります。
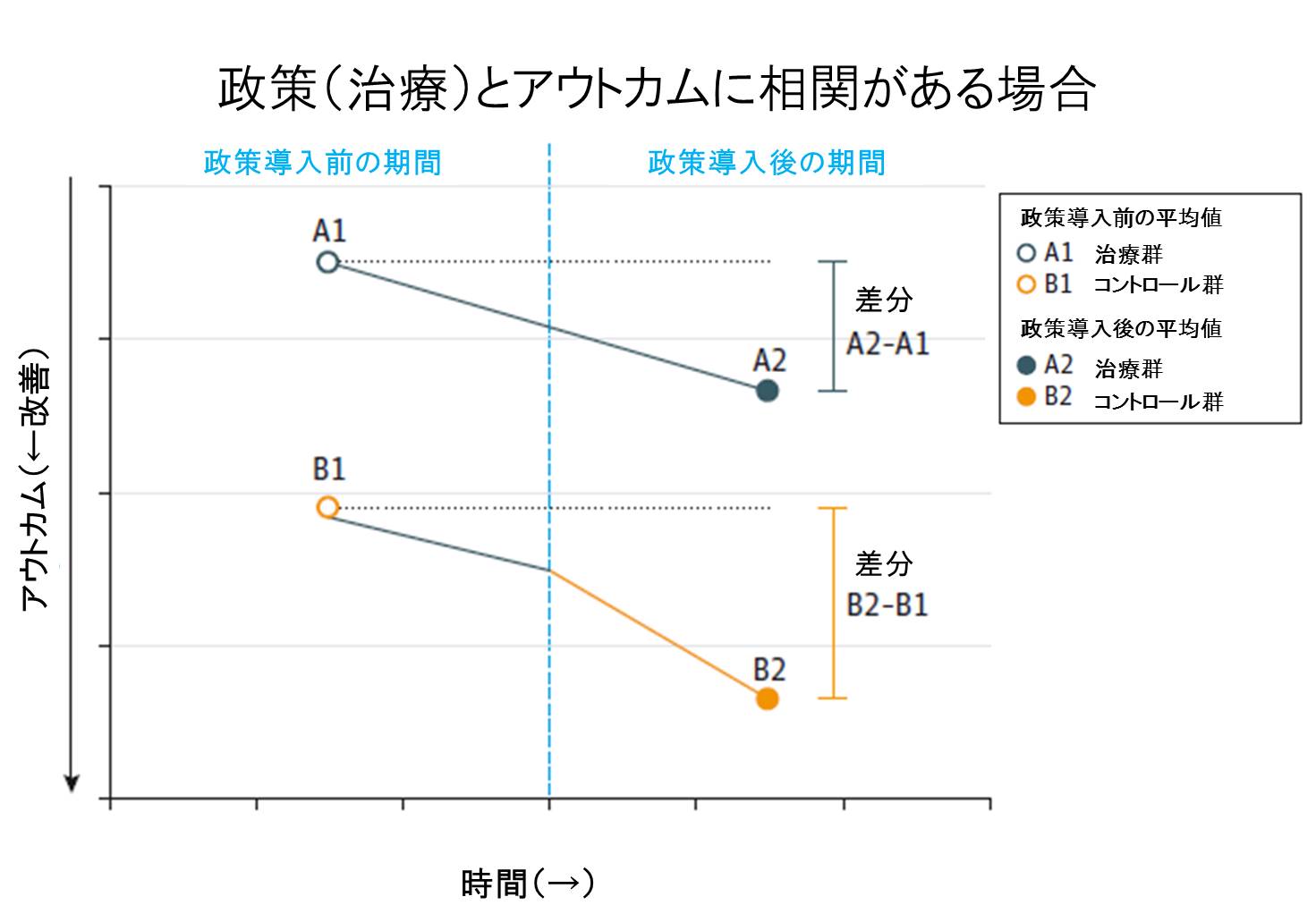
(出典:Dimick & Ryan, JAMA 2014を一部改変)
DIDが正しく政策の評価を推定するためには2つの仮定(Assumptions)を満たす必要があります。その2つの仮定とは、(1)平行トレンド仮定(Parallel trends assumption)と(2)共通ショック仮定(common shocks assumption)です。
平行トレンド仮定はCommon trend assumptionと呼ばれることもありますが、介入群とコントロール群において、もし仮に政策が導入されかったとした場合、アウトカムは平行したトレンドを描くというものです。上記の図でいうと、介入群とコントロール群で線の「傾き」が同じであるという仮定です。これは、コントロール群が、介入群の反事実(もし仮に政策が導入されなかった場合のアウトカムの推移)として適切である必要があるからです。政策導入前にアウトカムが複数回測定されている場合、それらのデータにおいて介入群、コントロール群の両群のアウトカムのトレンドが平行であることを示すことができれば、この仮定が妥当であることを証明できます。逆に、政策導入前のアウトカムのトレンドが二群で異なる場合にはDIDは不適切な研究デザインであると考えられます。
共通ショック仮定とは、政策導入前のアウトカム測定と、政策導入後のアウトカム測定との間に、アウトカムに影響を与えるような「別のイベント」が起きていない、もしくは起きているとしたら二群に対して同じように作用しているという仮定です。もし政策導入と同じタイミングである他のイベントが起きており、それが介入群のアウトカムだけに影響を与えていた場合、DIDで推定した効果が政策の効果なのか、その「別のイベント」の効果なのかが分からなくなってしまうからです。
差分の差分分析(DID)の実際の解析方法
実際にDIDを使うためには回帰分析(regression analysis)を使います。回帰分析さえできればよいので、どんな統計解析ソフトでもDIDを行うことができます。
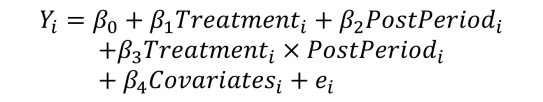
上記のような回帰分析を用います。この数式で、Yはアウトカム、Treatmentは介入群(Treatment=1)コントロール群(Treatment=0)のどちらであるか、PostPeriodは政策導入前のデータか(PostPeriod=0)それとも導入後に測定されたデータか(PostPeriod=1)、そしてCovariates(共変数)にはそれ以外のすべての補正因子が入ります。各変数の右下にアルファベットの i が付いているのは、各個人のデータを表しているからです。つまり、1人目の対象者はi = 1、2人目はi = 2と言った具合になります。最後のeは残差(residual)と呼ばれるもので、回帰分析の予測値と実際のデータの値との差を示します(注)。アウトカムが連続変数である場合、最小二乗法(OLS:Ordinary Least Squares)と呼ばれる方法がしばしば用いられますが、OLSはこの残差の二乗の合計を最小にするようにモデルをフィットする方法論になります。
(注)残差e(Residual)に関係する概念として、誤差項u(Error term)があります。残差は実際のデータを用いて推定された回帰モデルから算出される予測値と、実際に観察されたデータとの差を表します。一方で、誤差項は真の回帰式(実際には分からない)から求められる値と、観察された値との差を意味します。経済学では、誤差項は「Yの決定要因のうち回帰モデルの右辺に含まれた説明変数以外のものすべてを含んだもの」であると解釈します。言い換えると、もしYの決定要因のうち重要なものが、データがないなどの理由で回帰式に説明変数として含まれていない場合には、それはすべて誤差項に含まれると仮定します。


DIDの回帰式をSTATAでフィットさせて見ましたが、DID推定の結果が有意で無いと出ました。何を検討し直せばいいのでしょう。
いいねいいね
Mutolliro様、コメントありがとうございます。アウトカムの変数がbinaryであればロジスティック回帰を、正規分布しておらずどちらかに偏った分布であればNegative binomialなどそのデータの分布に合った回帰モデルを選択することが重要です。サンプルサイズが小さすぎればunder-poweredである可能性があるので、その場合にはサンプルサイズを増やす必要があると思います。データの分布も正しく設定しており、サンプルサイズも十分なのであれば、「介入」が「結果」に何の影響も与えていないと結論付けるのが妥当だと思います。その場合には検討しなおす必要は無く、「関係が無い」と結論付けるのが良いでしょう。
いいねいいね
Mr Tsugawa
Thank you for your introduction about DID. It’s easy to understand and give me a great help.
However, only one thing confused me a lot. It’s the figures in your article.
Though reading, I thought B is for Treatments and A is for Controls.
In the figures, they said that “A1 治療群” and “B1 コントロール群 ” that is the converse.
I wonder if that is a tiny mistake or just I misunderstand something?
-A foreign student in Japan
いいねいいね: 1人
carder team – carders team, carding forum
いいねいいね